|
第一次写和工作密切相关的文章,却无从下手,胡乱写起,纯当总结。
设备负载监控属于硬件级的基础监控,比设备基础监控粒度要粗一些,属于设备基础监控上一层的硬件监控,适合于数量较大、具有集群特性的硬件综合指标监控。当然,其监控数据来源仍为单机设备基础信息。
单机基础硬件指标大概包括CPU使用率、内存使用率、磁盘I/O、磁盘空间使用率、网卡出入包量、网卡出入流量、平均负载等。那么各种业务逻辑可能对这些指标都会有所侧重,例如WEB服务器比较侧重CPU、包量、流量,而DB比较侧重磁盘I/O、CPU使用率,CACHE则更关注内存使用率、CPU使用率等。对于数量庞大、类型不一的服务器,不可能关注到这么细致的数据信息,所以必须在几个维度进行汇总以便更好实现服务器管理。
那么设备负载监控系统的设计目标是什么呢?大概总结有以下几点:
- 减少管理单元,提高维护效率;
- 方便查看业务总体负载状况;
- 尽快发现高负载设备以便及时增加设备缓解业务压力;
- 减少空闲设备量,提高设备复用率,降低设备成本;
- 发现负载均衡方面的问题
要实现以上几个目标,首先需要将服务器分门别类。如WEB、DB、CACHE、业务逻辑等。上面提到,这些设备应该具备集群特性,其大概形式如下:
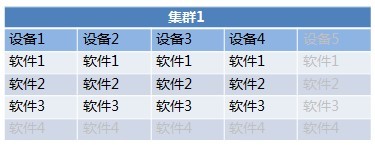
集群示意图
如上图所示,除灰色部分外,该集群拥有4台一样的设备,每台设备上均安装有1、2、3三种软件,这样这些设备的正常运行状况应该基本一致。当该集群呈现负载较繁忙的状况的时候,可以比较容易复制1-4号设备以增加一台一样的5号设备来降低业务负载。而当该集群负载较空闲的时候,可以将第4号软件部署于该集群下以充分利用设备性能。
在该集群负载均衡的状况下,单机的负载状况表现出来的特征,应该就是该集群的负载特征,通过管理集群即可映射到管理单机设备,假设有1000台设备,每个集群50台,那么只需要管理20个集群即可,管理单元明显减少。
在现实情况下,其实无法达到百分百负载均衡,所以还是需要一些算法计算集群的指标。最基本的算法就是MAX、MIN、AVG了。这三个基本可以处理90%以上情况。我曾经设计过比较复杂的公式支持,后来发现基本上用不上。当然算法越粗暴误差越大。如使用MAX计算CPU使用率,那么假如该集群下某台设备由于特殊原因CPU一直占用较高,那么表现在集群上的CPU使用率也会较高,而实际情况可能这个集群相对空闲。而使用AVG求平均数值,那么一些异常设备将会被淹没不能及时发现,所以这里需要根据业务特性做一些权衡和取舍。当然不建议使用更复杂的算法,因为配置维护成本比较高,而且数值计算结果不直观。
为了修正个别设备引起集群高负载的问题,引入了高负载设备数的指标。假如该集群负载较高且高负载设备数也高于某个比例(如50%)则认为该负载值准确描述集群压力状况。
出处:蓝色理想
责任编辑:bluehearts
上一页 下一页 WEB监控体系之设备负载监控 [2]
◎进入论坛网络编程版块参加讨论
|







