|
在完成自动sharding之后,可以使用mongo看一下结果:
> use dnt_mongodb
switched to db dnt_mongodb
> show collections
posts1
system.indexes
> db.posts1.stats()
{
"sharded" : true,
"ns" : "dnt_mongodb.posts1",
"count" : 161531,
"size" : 195882316,
"avgObjSize" : 1212.6608267143768,
"storageSize" : 231467776,
"nindexes" : 1,
"nchunks" : 5,
"shards" : {
"shard0000" : {
"ns" : "dnt_mongodb.posts1",
"count" : 62434,
"size" : 54525632,
"avgObjSize" : 873.3323509626165,
"storageSize" : 65217024,
"numExtents" : 10,
"nindexes" : 1,
"lastExtentSize" : 17394176,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 2179072,
"indexSizes" : {
"_id_" : 2179072
},
"ok" : 1
},
"shard0001" : {
"ns" : "dnt_mongodb.posts1",
"count" : 99097,
"size" : 141356684,
"avgObjSize" : 1426.4476623913943,
"storageSize" : 166250752,
"numExtents" : 12,
"nindexes" : 1,
"lastExtentSize" : 37473024,
"paddingFactor" : 1,
"flags" : 1,
"totalIndexSize" : 3424256,
"indexSizes" : {
"_id_" : 3424256
},
"ok" : 1
}
},
"ok" : 1
}
通过上面的结果,可以出现16万条记录均分在了两个sharding上,其中shard0000中有62434条,shard0001中有99097条。下面看一下这两个sharding-chunk的分布情况(图中的错误提示‘输入字符串格式不正确’主要因为运行环境与编译程序使用的环境不同,一个是64,一个是32位系统):
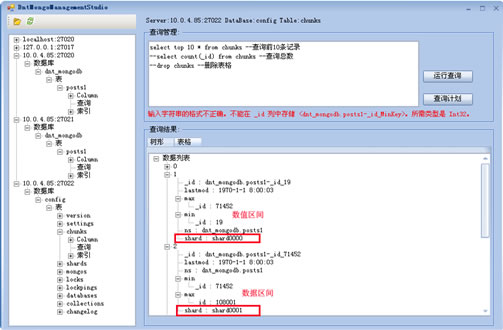
可以看到数据被按区间自动分割开了,有点像sqlserver的数据分区表,只不过这是自动完成的(目前我没找到可以手工指定区间上下限的方式,如有知道的TX可以跟我说一下)。当然在本文中的测试中,共有5个chunk,其中4个位于shard0001,这种情况可以在每次测试过程中会发生变化,包括两个sharding被分配的记录数。另外就是在mongodb移动过程前后会在shard0000上生成一个文件夹,里面包括一些bson文件,名字形如(表格+日期等信息):
该文件主要包括一些数据库,表结构及相关记录等信息,我想应该是用于数据恢复备份啥的。
好的,今天的内容就先到这里了。
原文:http://blog.csdn.net/daizhj/archive/2010/09/07/5868360.aspx
本文链接:http://www.blueidea.com/tech/program/2010/7953.asp 
出处:CSDN
责任编辑:bluehearts
上一页 基于Mongodb进行分布式数据存储 [3] 下一页
◎进入论坛网络编程版块参加讨论
|








