|
如果需要保留其他的用户信息,例如cookieid,登录名,访问时间等信息,这个字符串会更加复杂些。如果我们研究目的比较简单,还可以进一步处理,如果不需要对步长信息进行分析,我们可以去掉相邻重复的一些数据,把上式简化为” a,c,0,a,p,c,0,c,t,0”。
这个过程请参看图2中的①和②,由此我们可以得到多个用户的路径的字符串形式的文件。
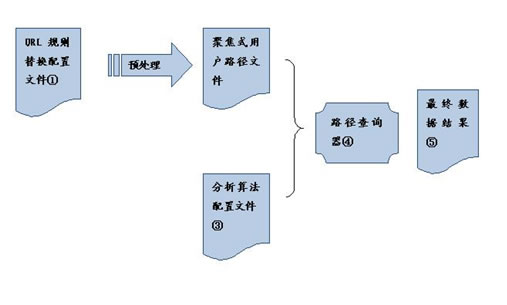
图2
得到这个聚焦式用户路径文件后,我们就可以对这个字符串文件进行分析了。例如,我们需要计算a页面后有多少个c页面,需要能忽略中间的翻页页面(p页面)。在上例中的这个用户的字符串中,就是1个用户,2次c页面。如果在访问了其他页面之后再访问c页面的行为也可计算入内的话,那就是1个用户,3次c页面。
接下来就是分析的样本量问题。一般分析过程中会讲究“多而全”,但数据量大到一定级别,分析1/10甚至1/100人群与分析全样本所得到的结果相差无几,花费很多资源去提升一点精确度是一件很得不偿失的事情。因此可以酌情分析小样本量,节省分析成本。
由于目标页面业务的独特性,每次需要分析的方式也很个性化。路径查询器可以灵活应对各种查询。例如,我们需要计算a后面有t的人次,a后面紧跟着c的人次,行为符合某种模式的用户数有多少等等。需要统计的模式在分析算法配置文件(图2中的③)中进行配置,查询器会计算并导出最终结果。
另外,查询器还支持分类信息查询,根据用户路径文件的配置信息,对每种分类的人群分别查询,或者导出符合某种模式的人群Cookieid,用户名等,与其他数据存储媒介联接,取得这部分人群的其他信息,从而进行综合分析。
这种方法优点在于比较灵活,如果网站的URL规则比较规范,在配置过程中可以多采用正则表达式,从而可以发现更多有趣的现象。
本文链接:http://www.blueidea.com/tech/site/2010/8017.asp 
出处:alibaba.com中国站
责任编辑:bluehearts
上一页 聚焦式分析 [1] 下一页
◎进入论坛网站综合、网页制作版块参加讨论
|







