|
3.2.2.2数据的版本管理
每一个数据我们都给它一个版本,初始值为0,以后对数据的每次变化时,都给它一个新的版本号,以便用户进行调试或查询。
3.2.2.3数据的变更记录
对数据的每次变更都记录下来,形成一个历史记录,以便用户进行调试或查询。它可以与基线管理配合使用。
3.2.2.4数据的基线管理
将数据的某个版本作为一个基线,以后每次的变更都是针对这个基线的增量。
3.2.2.5数据的全文搜索
3.3非功能性需求
3.3.1分布式的需求
本数据库暂时对分布式方面的要求不高,或者说暂时不需要,在第一个实现中不与考虑.
3.3.2数据库事务的要求
虽然本数据库对分布式要求不高,但对事务时要求却很高,必须有完整ACID支持,幸运的是我们有下层的RDBMS来保证,我们只要提供封装就可以了。
3.3.3移植的要求
这个分为两个方面
一、对RDBMS数据库的移植要求,暂时不要求支持多种数据库,仅支持PostgreSQL.
二、对操作系统方面的移植要求,暂时要求支持windows和redhat。
4.设计思路
本数据库的架构大致如下
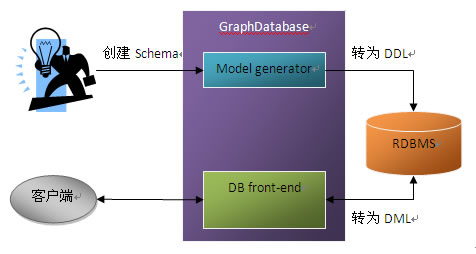
<!--[if !mso]-->
整个数据库分为两大部分:Model generator负责将用户创建的数据类图生成为多个RDBMS表或视图的创建或修改语句。而DB front-end 则负责将客户端的请求转化为一个或多个SQL语句。总之尽量让RDBMS来完成工作.
那么本数据库的对象模型如何映射到RDBMS上呢?在说明这个之前我们先来介绍一下PostgreSQL数据库的两个功能:
<!--[if !supportLists]-->
<!--[if !supportLists]--> 一、<!--[endif]-->表的继承二、递归查询,或者叫公共表表达式 <!--[endif]-->(Common Table Expression,CTE)<!--[endif]-->
现在聪明的你差不多应该明白我的想法了, 我们按数据的定义中的UML类图中定义的那样子在RDBMS中定义5个基本的表,其它用户定义的派生条目(item) 、派生关系(relationship)和派生属性组(attributeGroup)则各对应一个表,所有的这些表的继承均与类的继承关系完全一致。
出处:博客园
责任编辑:bluehearts
上一页 GraphDatabase在关系数据库中的实现 [6] 下一页 GraphDatabase在关系数据库中的实现 [8]
◎进入论坛网络编程版块参加讨论
|







